
AWS SageMaker Pipeline - Part 1: Creating Model Registry and Feature Store Group
- Arash Heidarian
- Oct 23, 2024
- 7 min read

Updated: Dec 12, 2024

Table Of Content
What is Feature Store?
With no wasting time, lets dive in! OK, so why is a Feature Store Needed? What Problem Does it Solve?
Consistency Between Training and Inference: One of the major challenges in ML workflows is ensuring that the features used for training the model are exactly the same as those used during inference. Discrepancies between training and inference features (also called data leakage) can lead to poor model performance. A feature store ensures that both training and inference share the same features by storing them in a central repository.
Feature Re-usability: Teams often create the same features multiple times across different projects. This leads to inefficiencies and redundancy. With a feature store, features can be created once, then stored and reused across projects, reducing development time and effort.
Real-Time Feature Serving: Models need to make predictions in real-time (e.g., fraud detection or recommendation engines). Feature stores provide fast access to real-time data (via online stores) for quick predictions. It also provide a slower-access to bigger portion or batch of data for model training, known as Offline Store. Lets have a closer look into these online and offline concepts:.
Online vs Offline Feature Store
1. Online Feature Store:
Purpose: The online feature store is optimized for low-latency, real-time access to features. It is mainly used during inference, where quick lookups of features are needed to make real-time predictions.
Use Case: Suppose you are working on a recommendation system, and when a user logs in, the model needs to predict the top products for that user in milliseconds. The online store can serve the user’s historical behavior features instantly for the model to predict.
2. Offline Feature Store:
Purpose: The offline store is designed for large-scale, batch processing. It is used for training models, where historical features are needed to train or retrain models with past data.
Use Case: If you are training a model to detect fraudulent transactions, you’ll need historical transaction data and their associated features to train your model. This data would be pulled from the offline store in batch mode.
The offline store in SageMaker is built on Amazon S3, which provides the scalability to handle large datasets, and is integrated with SageMaker for training workflows. Data can be fetched using Athena query, although files are stored in Parquet format in S3, but you don't need to worry about it, as you can access all you need using a simple SQL query.
Create Feature Group
For the purpose of this post, I just create a dummy DataFrame. You can build the DataFrame using your own data of course.

Setting Variables & AWS Libraries There are few essential packages which are related to SageMaker and FeatureStore:
FeatureGroup: Class used to define and manage a collection of features within SageMaker Feature Store.
sagemaker.Session(): Establishes a SageMaker session for managing and interacting with SageMaker resources.
get_execution_role(): Retrieves the IAM role that allows SageMaker to access other AWS services (e.g., S3, Feature Store).
sagemaker_client: A Boto3 client used to interact specifically with SageMaker services.

Load Feature Definition
Now lets initiate the Feature Group, and load its definition:

Create Feature Store
Finally, its time to build Feature Store. To get this done, we need to set few parameters:
feature_group.create(): Initiates the creation of a new feature group in the SageMaker Feature Store.
s3_uri: Specifies the S3 path where offline feature store data will be stored (using the defined bucket_name).
record_identifier_name='customer_id': Sets customer_id as the unique identifier for each record (similar to a primary key in a database).
event_time_feature_name='event_time': Defines the event_time feature, which tracks the time when the event (e.g., a transaction or interaction) occurred.
role_arn=role: Uses the previously retrieved IAM role to grant permissions for SageMaker to access AWS resources like S3.
enable_online_store=True: Enables the online store for low-latency, real-time access to features.
description: Adds a description for the feature group.
tags: Attaches metadata (tags) like environment, project name, and owner for easier resource management.

List existing Feature Groups
Lets check if we have created the Feature Group successfully. This code block checks the details of the created feature group and lists all feature groups currently available in the AWS SageMaker environment.

Now lets check the Feature Store, from SageMaker Studio. Click on FeatureStore from Left side menu, you should be able to see the Feature Groups you have created so far:

What is Model Registry?
The Model Registry is a centralized, managed repository within SageMaker that helps you track, version, and manage machine learning (ML) models throughout their lifecycle. It ensures efficient model deployment, tracking, and collaboration, especially in production environments.
Key Features:
Model Versioning: You can store multiple versions of a model, helping to track changes over time and maintain an organized history.
Approval Workflow: Models can be tagged as Pending, Approved, or Rejected, enabling a systematic review and approval process before deploying models into production.
Model Metadata: Stores important metadata about models, such as the model’s parameters, accuracy, and other performance metrics.
Deployment Integration: Registered models can be easily deployed to SageMaker Endpoints, making it simpler to move models from development to production.
Audit and Tracking: You can audit the history of the model, including who created it, what changes were made, and how it was deployed.
Now lets talk about Model Group. A Model Group is a collection of related models in the Model Registry that belong to the same project or use case. It is used to organize different versions of a model.
Key Features:
Organizing Models: A Model Group helps group related models together. For instance, if you're iterating on a fraud detection model, each version of that model can be part of the same model group.
Version Control: Model versions within a group are tracked, allowing you to compare different versions of the same model.
Stage Transitions: Models within a group can have different statuses, like Pending Approval, Approved, or Rejected, streamlining the governance of model promotion to production.
Example Workflow:
Train and Register a Model: After training a model, you register it in the Model Registry under a Model Group. Each model version is stored with its metadata.
Model Versioning: Over time, as new models are trained, they are registered as new versions under the same Model Group.
Review and Approval: Teams can review new model versions, set their status (e.g., Pending, Approved), and decide which versions should be deployed.
Deployment: Once a model version is approved, it can be deployed directly from the Model Registry to a SageMaker endpoint for inference.
Long story short, Model Registry manages the lifecycle of ML models, tracking versions, approvals, and deployment status. While, Model Group organizes different versions of a model, enabling clear version control and collaboration.
Create Model Group
Lets create and dedicate a Model Group to models related to this blogpost.
Setting Variables & Libraries
This code sets up the environment and configuration for creating and working with a Model Group in AWS SageMaker, as well as defining S3 bucket paths for model storage and pipeline input/output. I briefly explain few essential parameters, as it is important to know what they actually do, feel free to adjust it as you wish:
model_package_group_name: Creates a unique name for the model package group, combining "SampleModelGroup" with the current time (in seconds). This ensures uniqueness for tracking and versioning models. So the chance of ending-up with multiple Model Group, with the same name will be close to 0!
bucket_name: Specifies the S3 bucket where the input, output, and model data will be stored.
S3 Paths:
main_folder_prefix: Defines a root folder name in the S3 bucket (AbalonePipeline for our example) for organizing resources.
input_prefix: Creates an S3 path under the main folder for storing pipeline inputs (AbalonePipeline/input).
output_prefix: Creates an S3 path for storing pipeline outputs (AbalonePipeline/output).
model_dir_path_uri: Specifies the full S3 path where the model artifacts (trained models) will be stored.
model_pred_machine_size='ml.t3.medium': Defines the SageMaker instance type (ml.t3.medium) that will be used for hosting model predictions. Check available instances in your region.

Creating the Model Group
Using the code below, we create the model group! Peace of cake!

Now lets check the Model registry, from SageMaker Studio. Click on Models from Left side menu, you should be able to see the Model groups you have created so far:

What is next?
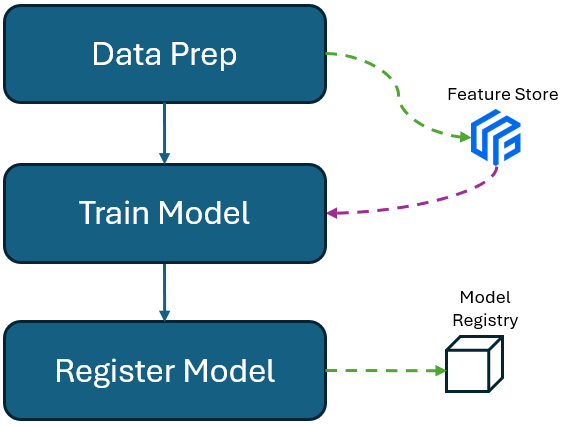
In my next blog post, I will guide you through the complete process of building a robust machine learning pipeline using AWS SageMaker. This pipeline will encompass several critical stages:
Ingesting Preprocessed Data into Feature Store: I will start by demonstrating how to efficiently ingest your preprocessed data into the SageMaker Feature Store. This step is essential for managing and storing your features in a centralized repository, making them readily accessible for model training and deployment.
Training Your Model with Data from Feature Store: Next, I will show you how to retrieve data from the Feature Store for model training. You'll learn how to ensure consistency between training and inference by using the same features stored in the Feature Store, thereby improving model performance and reliability.
Registering the Model in the Model Registry: Finally, I will walk you through the process of registering your trained model in the SageMaker Model Registry. This will include versioning your model, setting up approval workflows, and managing model metadata. The Model Registry will streamline the transition of your models from development to production.
Join me as I explore these steps in detail, providing practical insights and code examples to help you leverage AWS SageMaker effectively in your machine learning projects. Whether you're a beginner or looking to enhance your existing knowledge, this post will equip you with the tools to create a seamless machine learning workflow.
From The Inside
What makes us superior to them is our emotional depth
"In my imagination, under a rain which doesn't exist,
I arrive home, via a street which doesn't exist,
You sit in front of me, taking some rest, I pour you some tea, in a cup which doesn't exist, I sing you a song, flowers bloom, I put them in a vase, which doesn't exist,
I gaze into your eyes and beg, can you hold my hand, in your hands, which do not exist,
When you want to leave, I hold my tears and ask, Please don't leave,
You go away and leave me with the memories of my beloved guest, who doesn't exist
You are gone, and after you, the imaginations running wild,
Believe me its so hard to accept, that you don't anymore exist!"
7+5

Comments