
MLOPS .vs. DEVOPS
- Arash Heidarian
- Feb 18, 2022
- 4 min read

Updated: Mar 30, 2022

Photo by Dietmar Becker on Unsplash
Due to lot of similarities between DEVOPS and MLOPS, usually teams get confused on using the right term and approach. Although general concepts are still in common between the two, sometimes same terminology in DEVOPS has absolutely different meaning in MLOPS. In this post, I try to explain what is MLOPS and why we need it. I also briefly mention why and how MLOPS is different than traditional DEVOPS used by software engineer teams. Hopefully it helps data scientists and software developers and DevOps engineers understand each other better and collaborate easier.
Why do we need MLOPS ?
I have developed lot models for different companies. I always like to open my favorite IDE, start to code and improve my models over the time. I was happy, the companies were happy. In reality, things in a short term was sweet for me as a data scientist, but things were getting annoying after a while. why ? Well, after a while, new set of data emerged, pattern over the data changed, then I had to modify my hyper parameters, or even data preparation had to be modified, because sometimes new categories or data features were added up. Or just managers started to realized that maybe its not a bad idea use some other features from other datasets (either external data or just data from another department). I was asked to check and see if adding new data would improve the model or not. Let alone the nature of initial features which could get changed over the time. Changing the data was just a tip of an iceberg. Because I had to modify the models to see if it gets any better. Sometimes new adjustment to the model didn't give us good results in long term, sometimes the new datasets and features were just unnecessary as they increased the cost to the favor of many minor improvement. Here nightmare begins: you need to travel over all the changes in data and the model, to chose the best model and best data preparation approach. Then make the new model available to business to be used. Things were getting really messy under the hood. I had to highly rely on manually checking documentations and codes to refresh my memory and do lot of manual comparisons to pick the best model and data feature, put it in testing mode for a while, and then pass it to last stage for being used by business. Well, I could get along, but things can be much more organized and easier to maintain using MLOPS process.

Terminologies
Before we start to explain what MLOPS does for us and how it is different than DEVOPS, we need to understand some acronyms and terms used widely in this area:
Pipeline: Series of subtasks which need to be executed one after each other automatically, in order to accomplish a bigger task.
CI: stands for Continues Integration. Used when a codes are modified, which means new codes should be integrated automatically.
CT: stands for Continues Training. The concept is same as CI, but CT is only used in MLOPS. In fact, any change applied to codes, leads to re-train the existing model.
CD: stands for Continues Deployment. It usually comes after CI, where modifying code, lead to modified final product, and it should be deployed into the testing or production environment.

Comparisons
Local environment: There is no significant difference here. Either in DEVOPS or MLOPS, developers/data scientists use their personal system to write their initial codes, experiment with it and play with different commands. Once they feel more confident with their codes, they start to push their codes into Dev pipeline.
Development:
In DEVOPS dev environment is where software developer start to test their codes into dev environment, to make sure it is executable in the dev environment. Once expected outcome is met, they move their codes into testing.
In MLOPS, dev environment is where data scientists start to create components to accomplish different tasks, based on their experiments in their local machines. For instance, if they wrote a code in their local machine to do data preparation, in dev, it should be encapsulated as a component which is acceptable by dev environment. Also a component should be created for model training. Finally all the model metadata, feature set and model itself should be stored. At this stage, data scientists can also start to monitor the model performance based on training and testing datasets. This helps them to understand how their retrained model is performing compared to previous versions. Once results from the retrained model looks improved, the model can be sent to testing/staging. This stage requires continuous integration (for data prep), and continues training (for model training), when a change or new model is implemented.
Testing/Staging:
In DEVOPS, testing environment is where testers start to do functional and user acceptance testing to make sure the code is working under different test conditions. Once the acceptance criteria are ticked by testers, the codes are ready to be deployed into production. This stage requires continuous integration, when a new functionality is added or a bug is fixed.
Fore MLOPS, using Staging term is more appropriate. At this stage, a stored model which is usually in pkl or onnx format, is downloaded. Then it is deployed to be used for endpoint and batch prediction/storing. Once the model is deployed, it can be tested by passing data into it, and expect scores/predictions generated by the model. Once it is tested successfully, it will be moved to production. This stage requires continuous deployment when a new/retrained model is pushed through.
Production:
In DEVOPS, Production is where codes are placed in live environment officially and end-users can start to use the newly developed/fixed functionality. This stage requires continuous deployment when a new functionality is added or a bug is fixed.
In MLOPS, in fact production is very similar to staging with some minor differences. That is, a task downloads and deploys the stored model (usually in pkl or onnx format). Then it goes live and becomes available for endpoint or batch prediction/storing for end-users. In production, data, model responsiveness and accuracy is monitored over the time. Model and data governance is also another level which identifies access control and security. This stage requires continuous deployment when a new/retrained model is pushed through.
| MLOPS | DEVOPS |
Versioning | Data, Models and Code | Code |
Testing | Quality and validation on data and model: Check function behavior based on:
Building a Simulator (it can be another project/complex task). | Unit testing to check function behavior with predefined input and expected output. |
Contentious Integration, development, Training | CI/CD of Data pipeline feature engineering, prediction service, serving service and CT of model. | CI/CD of codes which form the application/software |
Hardware Required | Resource hungry, may take hours to weeks, may require lot of GPUs and memories. | May take minutes to hours, using an average machine with average CPU and memory. |
Human Resource Skill Set |
|
|
Conclusion
Hopefully this post can give you a clue to get some ideas on what is MLOP and how it is different to DEVOPS. The comparison of these two can get quite controversial, specially when pipeline discussions are added. I will publish another post, to explain MLOPS in deeper level.
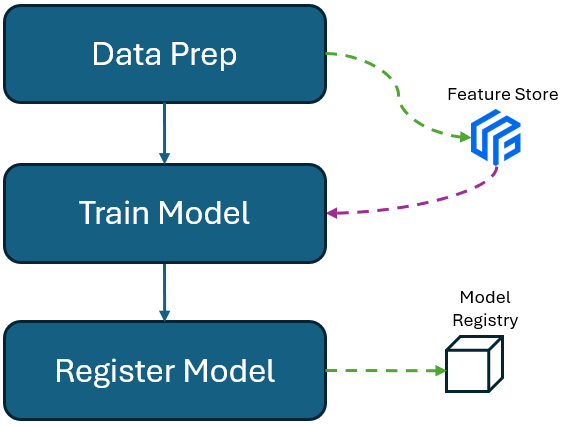


I like it. it is a good summary. Thanks