
Toward MLOps - Part 1: DataOps 101
- Arash Heidarian
- Oct 27, 2023
- 8 min read

Updated: Oct 30, 2023

Table of Contents
Expert Resource Allocation
Building a cloud-based solution for data-driven businesses that potentially leads to a robust MLOps infrastructure may seem straightforward initially, much like a "Lift and Shift" approach. However, as you progress, the journey can become more complex and intricate. Constructing an entirely new ecosystem demands not just a well-defined strategy and architecture but also a realistic and comprehensive understanding of available resources. Identifying and clarifying team members' responsibilities in the process of building a cloud solution is a fundamental and indispensable step. Although expert resource allocation can vary significantly from one business to another, there are general guidelines that can be applied to the majority of scenarios.
One aspect that can introduce confusion when constructing data-driven solution ecosystems, especially in larger organizations, is the roles of ML engineers, lead data scientists, and lead data engineers. In some instances, these roles may be amalgamated into a single position due to various factors. It's crucial to have a clear vision of who is responsible for what to avoid future conflicts, especially as the complexity of the ecosystem grows. Building ecosystems can become intricate, perplexing, and sophisticated much faster than expected.
Figure 1 illustrates a general expert resource allocation strategy for constructing a cloud-based data-driven ecosystem that ultimately leads to MLOps solutions.

One key element that individuals interested in MLOps and data science often attempt to bypass is the data engineering side. However, data engineering is an essential step. Lead data scientists or MLOps engineers cannot divorce themselves from the data engineering team's responsibilities.
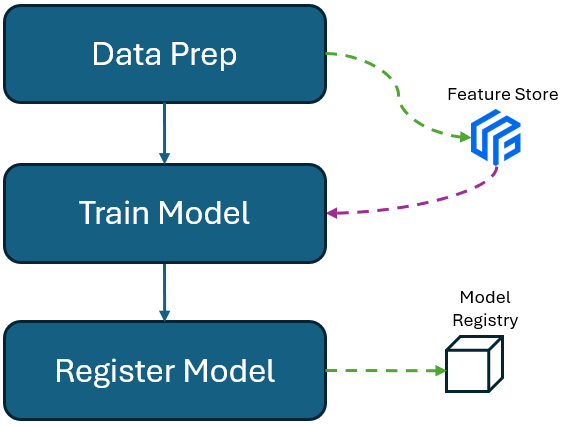
The data engineering team is responsible for creating ETL pipelines, data warehouses, data lakes, and data marts, depending on the business's size, requirements, and ultimate cloud migration goals. Once the required data is accessible via the chosen cloud platform, the data science team can begin to consume the data in the traditional way, such as data fetching and reading. However, to have a clear view of how data is consumed and how data science works can be maintained and monitored, it is essential to create a roadmap for building feature stores. Constructing a feature store necessitates understanding of data architecture and the prior work performed by data engineers. Data engineers should also comprehend how and why data scientists require access to specific data, fostering essential collaboration in feature store development.
Data scientists can commence model development, experiment tracking, and model registration. Once the development and experimental work reaches a stage suitable for business utilization, a registered model can be selected and tested in pre-production environments. This is where MLOps engineers play a crucial role. In pre-production, MLOps engineers are responsible for model deployment, endpoint management, and building model inference. If all goes well during testing and the model is deemed successful, it is ready to move to production. In the production phase, MLOps engineers again manage resources, endpoints, and monitor model performance over time.
It's important to note that the clear distinctions between different roles are not a one-size-fits-all solution. In practice, you often see overlapping responsibilities and collaboration between data engineering, data science, and MLOps teams, where one team member may be highly involved in the work of another team.
MLOps engineers responsibilities and capabilities is hugely depends on their background. We can have 3 types of MLOps, or I would say 3 species of MLOps engineers exist in the nature:
MLOps with Data Science background: These are experts who have years of experience in data science.They have deep understanding of data preparation, model training, choosing right algorithms and model performance analysis and monitoring.
MLOps with Data Engineering background: These people have spent their career on designing and building ETL pipelines and secure communication channels between different sources. They know best how architecture on the data side should look like and how a data lake and data warehouse should be managed.
MLOps with Solution Architecture background: These are experts with many years of experience in designing blueprints, documentations, cost management and leading team members. They probably have vague ideas of technical details on data science or data engineering, but have a deep and up-to-date knowledge of tools and technologies in the market. Not mentioning their skills on client facing and story telling.
All experts in these groups have understanding and even hands-on experience of experts in the other two groups, up to some level. The only remaining question is in what area the company has been limping over the course of executing data-driven solutions, using a traditional approach, before moving to clouds. The honest answer to this question would give us the clue of what type of MLOps engineer we need to assign to the work.
Data Engineering: Concepts
We will briefly delve into the realm of data engineering, a critical aspect of building analog solutions. As Figure 2 illustrates, data engineering encompasses a range of responsibilities aimed at collecting data from diverse sources and storing it in cloud-based data repositories. This process ensures data becomes accessible and usable within a unified target cloud platform.

ETL (Extract, Transform, Load) pipelines serve as the workhorses in this context. They fetch and extract data from various sources based on predefined triggers, such as scheduled events or data arrival triggers. ETL pipelines are responsible for two primary destinations: data warehouses, where data is structured and stored, or data lakes, where a blend of data in different formats, including unstructured data, resides. The choice between the two hinges on several factors, including business size and the intended purpose of the cloud services being developed.
If the focus is on data analytics, the derived data often originate from the data warehouse. This approach simplifies connectivity to analytical tools, making data analysis more accessible to business analysts and managers. In contrast, when the emphasis shifts toward data science and MLOps solutions, more extensive transformations of both structured and unstructured data may be required.
The process of transformation is a complex realm in itself, involving a plethora of techniques, tools, and architectural plans. It's important to note that there is no one-size-fits-all solution in this domain. The choice of transformation processes depends on the specific objectives and use cases tied to the data collected in the cloud.
Figure 3 shows some sample data transformation architectures suggested by Microsoft. Even the suggested architectures, require adjustments, and modifications, depending on organization size, business type and ultimate purpose.

Having a well-defined data engineering solution is not only essential for simplifying data access for data scientists and business users but also plays a pivotal role in managing budgets effectively. Every operation in the cloud comes with associated costs, and having a clear purpose guides prudent budget allocation for ETL and transformation processes. This alignment between objectives and resource allocation is crucial for optimizing cloud-related expenses and ensuring cost-effective operations.
Data Engineering: Tools
When it comes to selecting the right tools for data transformation and data engineering, it's essential to take a step back or even a step forward, involving the data science team in the decision-making process. The first crucial consideration is to understand whether they intend to consume the data in a batch processing or real-time streaming form. The second fundamental question revolves around the nature of the data they plan to work with—structured or unstructured.
Having clarity on the answers to these two questions illuminates the path forward in terms of selecting the appropriate tools for data extraction, movement, and transformation. It also provides insights into whether the focus should be on investing more time and resources in a data lake or building a solid foundation for a data warehouse.
Figure 4, presented below, outlines various tools and options tailored to different scenarios.

While the figure highlights Azure cloud services, finding equivalent services in other major cloud platforms like AWS and GCP is a manageable task. Therefore, the responses to these two fundamental questions can significantly simplify decision-making and architecture design:
Batch or Real-Time: Determining whether data should be served in batch processing or real-time streaming mode is pivotal.
Data Lake vs. Data Warehouse: Balancing the use of data lake and data warehouse resources is critical in shaping the architectural framework.
These considerations guide the selection of tools and infrastructure, ensuring that they align with the data science team's specific needs and the overarching objectives of the project.
Feature Store: Concepts
All the brief introduction about data engineering work above at one main purpose and that's understanding of data structure infrastructure and serving points in order to build a proper features store without having the knowledge building features tools can make some either work overlap or duplication between data science tasks and data Engineers tasks.

A feature store is a critical component in machine learning and data-driven applications. It is a centralized repository for storing and managing the features or attributes used in machine learning models. Features, in this context, are the input variables or data attributes that machine learning models rely on to make predictions or classifications.
Here are the key aspects of a feature store:
Feature Management: A feature store serves as a central hub for organizing and managing features. It stores features in a standardized and structured format, making it easy for data scientists, machine learning engineers, and data engineers to access, update, and share features for model development.
Versioning: Feature stores typically support version control for features. This ensures that you can track changes to features over time, making it easier to maintain reproducibility and traceability in machine learning workflows.
Reusability: Features stored in a feature store can be reused across different machine learning projects and models. This promotes efficiency and consistency in feature engineering, as teams can leverage existing features for new projects.
Real-Time and Batch Access: Feature stores enable both real-time and batch access to features. Real-time access is crucial for online prediction and inference, while batch access supports offline model training and experimentation.
Feature Engineering: Feature stores may provide built-in feature engineering capabilities, allowing users to create new features from existing ones. This can streamline the feature engineering process and accelerate model development.
Scalability: Feature stores are designed to handle large volumes of data and a wide range of features, making them suitable for enterprise-level machine learning applications.
Data Governance: They often include features for data governance, ensuring that data is stored, accessed, and utilized in compliance with regulatory requirements and best practices.
The use of a feature store offers several advantages, including improved collaboration among data and machine learning teams, reduced duplication of effort, better model management, and enhanced model performance. It helps organizations build, deploy, and maintain machine learning models more efficiently and effectively by addressing common challenges associated with feature engineering and management.
Feature Store is not Data Warehouse
Concept of a feature store is relatively new and that's why many experts get confused by its similarity to data warehouses. Data scientists commonly employ Python scripts to craft training and testing datasets, unifying existing features from the feature store. These datasets are then transformed into file formats tailored to the specific machine learning framework in use, such as TFRecord for TensorFlow or NPY for PyTorch. In contrast, data warehouses and SQL systems presently lack the built-in functionality to generate training and testing datasets in machine learning-compatible file formats.

Conclusion
In summary, building a robust MLOps infrastructure in the cloud requires careful planning and resource allocation. Clearly defined roles within the data-driven ecosystem are essential, and expert resource allocation should align with your organization's specific needs.
Data engineering plays a crucial role in collecting and transforming data, with ETL pipelines serving as workhorses in this process. Proper data engineering is vital for data access and budget management in a cloud environment.
Choosing the right tools for data transformation and engineering is equally important, and it should align with your data science team's needs and project objectives.
We also introduced the concept of a feature store, a structured and reusable approach to managing machine learning features. This is distinct from data warehouses and offers significant advantages.
As we move forward in Part 2, we'll explore the construction of the Feature Store, architectural considerations for various scenarios, and MLOps planning for a sustainable data science solution. This series aims to equip you with the knowledge and tools needed for success in the dynamic world of data-driven solutions and MLOps.
Coming Up…
In Part 2, I will delve into a more detailed exploration of the construction of the Feature Store, shedding light on the architectural prerequisites essential for building feature stores tailored to diverse scenarios. Additionally, we will address the intricacies of designing and planning MLOps to ensure a robust and sustainable data science solution.


Comments